
1. CASE 1 - 함수의 관점에서
#재귀함수와 스택
import sys
sys.stdin=open("input.txt", "r")
def DFS(x):
if x>0:
DFS(x-1)
print(x, end=' ')
if __name__== "__main__": #스크립트실행시 가장 먼저 실행
n =int(input())
DFS(n)
2. 출력결과 1 2 3
3. 출력결과 1 2 3 인 이유
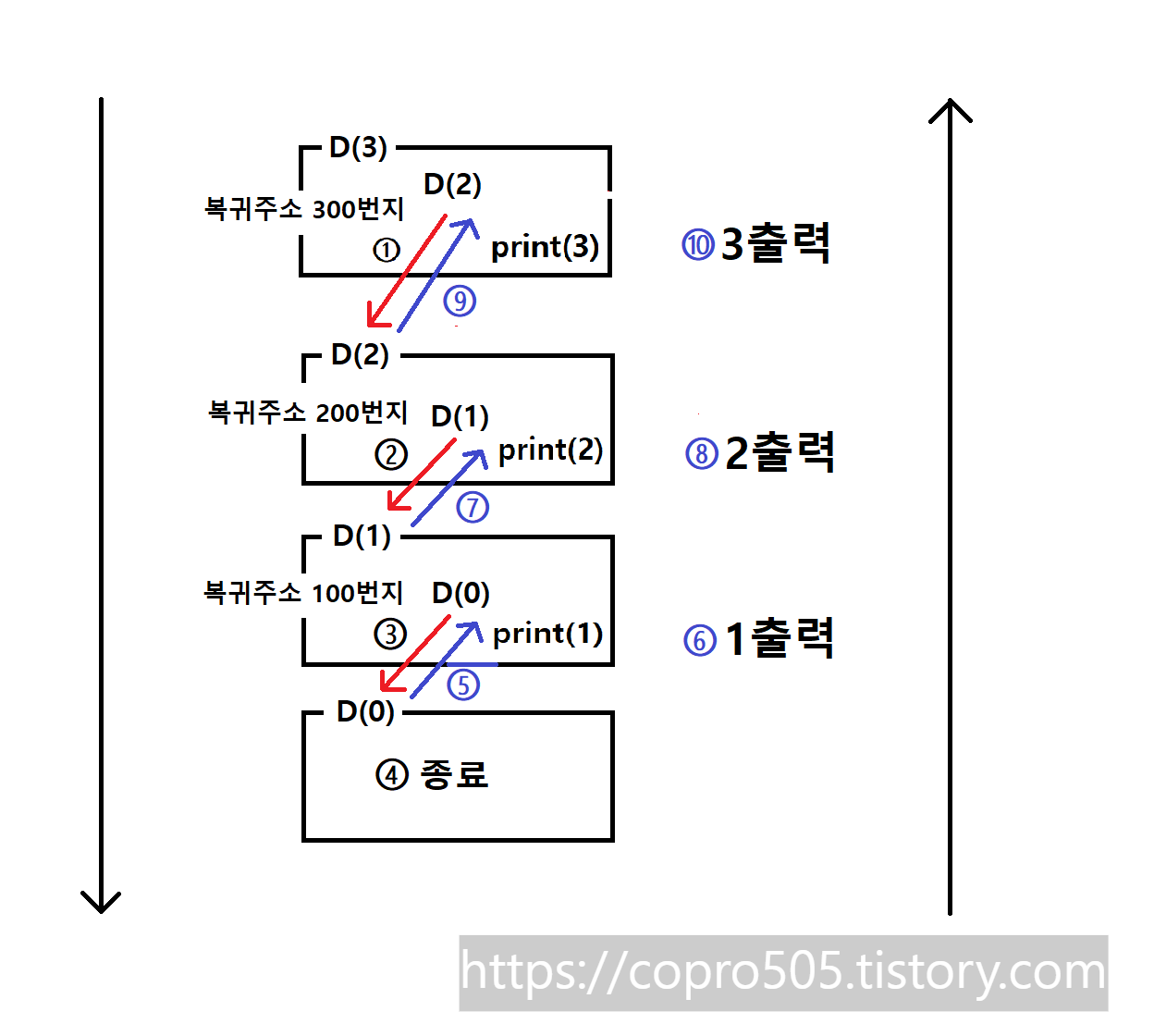
4. 보충설명
재귀함수의 경우 자기자신을 호출하는 함수를 말하는데, 재귀함수가 일단 호출되면, 재귀함수 아래에 있는 코드는 신경 안쓰고, 재귀함수 자신부터 처리한다. 그리고 호출했던 함수가 하나씩 종료되면서, 아래에 있던 코드를 처리한다.
최종적으로는 1 2 3을 출력하게 된다.
1. CASE 2 - 호출 스택의 관점에서
#재귀함수와 스텍
import sys
sys.stdin=open("input.txt", "r")
def DFS(x):
if x>0:
print(x, end=' ')
DFS(x-1)
if __name__== "__main__": #스크립트실행시 가장 먼저 실행
n =int(input())
DFS(n)
2. 출력결과 3 2 1
3. 출력결과 3 2 1 인 이유

4. 보충설명
재귀함수의 경우 자기자신을 호출하는 함수를 말하는데, print함수가 재귀함수보다 윗줄에 있으므로 print함수가 먼저 실행되고, 그 후에 재귀함수가 자기자신을 호출한다.
최종적으로는 3 2 1을 출력하게 된다.
1. 피보나치 수열 1단계 : 재귀함수(recursive)
def fibo(n):
if n==1 or n ==2:
return 1
return fibo(n-1) + fibo(n-2)
print(fibo(5)) #output 5
보충 자료1

2. 피보나치 수열 2단계 :메모이제이션(memoization), 재사용 O
→"타켓넘버"와 비교할 것
#재귀함수 호출시 mz리스트를 가져가기 위해 mz리스트를 매개변수로 사용함
def fibo(n, mz):
if(mz[n] != 0):
return mz[n]
else:
mz[n] = fibo(n-1, mz) + fibo(n-2, mz)
return mz[n]
def solution(n):
mz=[0] *(n+1)
mz[1]=1
mz[2]=1
return fibo(n, mz)
#test
print(solution(5)) #output 5▶ 배열에 저장해 놓았다가 맨 마지막에 배열에 담긴 값을 반환
보충자료2

3. 피보나치 수열 3단계 : 반복문을 사용, 재사용 O
def fibo(n):
mz=[0] *(n+1)
mz[1]=1
mz[2]=1
for i in range(3, n+1):
mz[i]=mz[i-1]+mz[i-2]
return mz[n]
#test
print(fibo(6)
점프와 순간이동
효율성 실패한 나의 첫번째 풀이 -반복문O, 재귀함수X
def solution(n):
if n == 1 or n == 2:
return 1
result = [0] * (n + 1)
result[1] = 1
result[2] = 1
for i in range(3, n+1):
# 이전에 구한 결과값을 재사용
if i % 2 == 0:
result[i] = result[i//2]
else:
result[i] = result[i-1] + 1
return result[n]▶n=10 인경우 D(10) D(5) D(4) D(2) D(1)만 순회하면 되는데,
▶ for문의 경우 때문에 n=1부터 n=10까지 전부 순회하므로 효율성이 떨어진다.
효율성 테스트를 통과한 풀이
def solution(n):
if n==1 or n==2://n==1일 때 건전비 사용량 1, n==2일 때도 건전지 사용량 1
return 1
if n % 2 ==0:
return solution(n//2)
else:
return solution(n-1)+1▶ n은 위치를 의미한다.
▶ return값은 건전지 사용량을 의미한다.
▶ n=0일 때는 1만큼 점프하여 건전지를 소비를 최초화한다.
▶ n=1일 때는 1x2=2 위치로 순간이동 할 수 있다.

▶ n: 짝수 --->f(n//2)
▶n: 홀수 ---->f(n-2) + 1 ←1만큼 점프하여 건전지 사용량을 최소화한다.
▶ n/2를 위 코드에 사용했을 때는 효율성 테스트를 못했는데,
n//2를 위 코드에 사용했을 때는 효율성 테스트에 통과를 했음
▶ 필요한 함수만 스캔해서 리턴값을 반환받자!!!
보충자료

타켓넘버-피보나치수열(메모이제이션)
나의 틀린 풀이
def solution(numbers, target):
return DFS(0, 0, target, 0)
def DFS(L, sum, target, cnt):
if L ==len(numbers):
if sum == target:
cnt+=1
return cnt
else:
DFS(L+1, sum-numbers[L], target, cnt)
DFS(L+1, sum+numbers[L], target, cnt)
numbers = [4, 1, 2, 1]
target = 4
print(solution(numbers, target))
성공한 나의 풀이 - 피보나치수열(메모이제이션)과 유사
def solution(numbers, target):
def DFS(L, sum, target, cnt):
if L ==len(numbers):
if sum == target:
cnt+=1
else:
cnt = DFS(L+1, sum-numbers[L], target, cnt)
cnt = DFS(L+1, sum+numbers[L], target, cnt)
return cnt
return DFS(0, 0, target, 0) #return으로 함수를 종료하는 것이 아니라 다른 함수를 호출한다.
numbers = [2,1]
target = 3
print(solution(numbers, target))
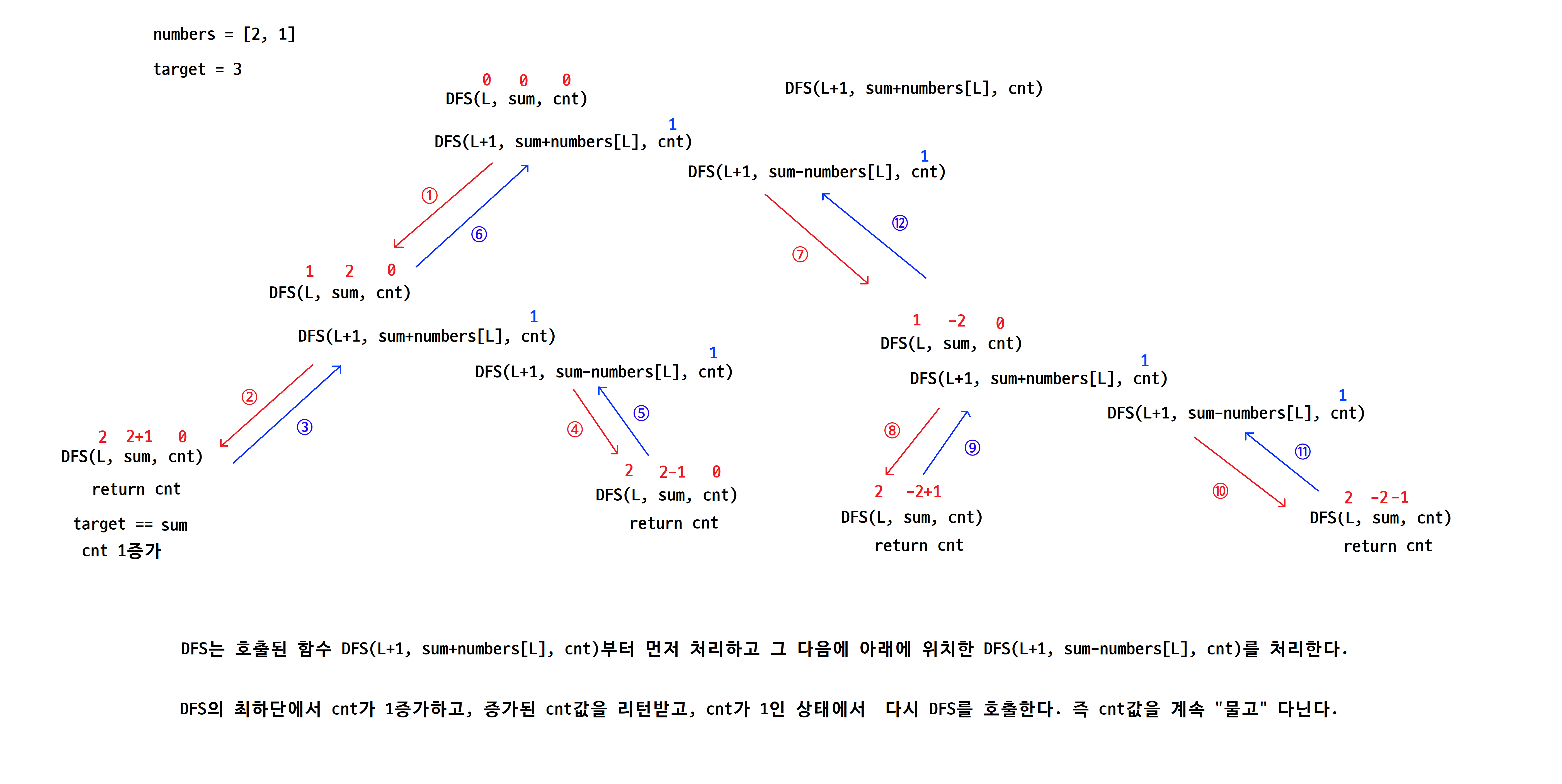
▶ cnt값을 update하면서, update가 반영된 cnt값을 끌고 가려면,
DFS의 리턴값으로 받아줘야 끌고 다닐수 있다.
▶ 함수의 마지막 줄에서 최종값으로 DFS에서 return을 해줘야 계속 DFS탐색을 하면서 cnt값을 끌고 간다.
▶ ③에서 증가된 cnt=1을 물고, ④으로 호출한다.
그런데 조건에 맞는 case가 없으므로 ⑤로 나올 때는 cnt가 여전히 1이다.
▶ cnt변수에 "값"을 저장해 놓았다가 함수가 최종적으로 종료되면, 그 값을 반환한다.
▶ target같은 경우 항상 같은 값이어야 하므로 별도의 조치를 취하지 않는다.
▶ 다만, sum의 경우 numbers의 요소를 더해서 값을 누적시켜야 되므로
sum-numbers[L] 또는 sum+numbers[L]를 해서 값을 누적시켜 나간다.
보충사항
"구슬을 나누는 경우의 수"를 보면
solution()함수의 리턴값을 result로 받아주고,
마지막 줄에서 return result하고 있다.
https://copro505.tistory.com/entry/%EA%B5%AC%EC%8A%AC%EC%9D%84-%EB%82%98%EB%88%84%EB%8A%94-%EA%B2%BD%EC%9A%B0%EC%9D%98-%EC%88%98
구슬을 나누는 경우의 수→순수(?) 조합 계산★★
다른 사람의 풀이 class Solution { public long solution(int balls, int share) { share = Math.min(balls - share, share); if (share == 0) return 1; long result = solution(balls - 1, share - 1); result *= balls; result /= share; return result; } } ▶
copro505.tistory.com
다른 사람의 정석 풀이
cnt = 0
def DFS(idx, numbers, target, value):
global cnt
N = len(numbers)
if(idx== N and target == value):
cnt += 1
return
if(idx == N):
return
DFS(idx+1,numbers,target,value+numbers[idx])
DFS(idx+1,numbers,target,value-numbers[idx])
def solution(numbers, target):
global cnt
DFS(0,numbers,target,0)
return cnt
▶ cnt를 global로 설정하면, 굳이 cnt를 매개변수로 하여 끌고 다닐 필요가 없다.
보충자료


재귀함수를 이용한 "순열"
arr = [] #순회대상이 되는 리스트
visited=[] #방문흔적을 기록할 체크리스트
result=[] #현재 순열을 담을 리스트
answer=[] #모든 순열을 담을 answer리스트
def dfs(L,r):
if L == r:
# answer.append(result) //틀림
answer.append(result[:])
return #리턴문이 있어도 되고, 없어도 된다. 재귀함수의 경우 조건이 만족되면, 호출된 스택은 종료된다.
else:
for i in range(len(arr)):
if visited[i] == 0:
result[L] = arr[i]
visited[i] =1
dfs(L + 1,r)
visited[i] = 0 # 다음 트리로 내려가기 위해서 이전의 방문처리를 롤백
def solution(n,r):
global arr, visited,result
arr=[i+1 for i in range(n)]
visited = [0] * len(arr)
result=[0]*r
dfs(0,r)
return answer
print(solution(3,2))
# 실행결과
# >>> [[1, 2], [1, 3], [2, 1], [2, 3], [3, 1], [3, 2]]일단 n과 r은 n은 1부터 n까지의 숫자를 의미하며, r은 뽑는 개수의 수를 의미한다.
n이 주어지면 1부터 n까지의 숫자가 들어간 배열 arr를 만든다.
예를 들어 n이 3이라면 1부터 3까지의 숫자가 들어간 arr = [1, 2, 3]이 만들어진다.
또한 숫자를 뽑아서 담기 위한 바구니인 result 리스트를 만든다.
n이 3이고, r이 2라면 3개중에서 2개를 뽑을 것이므로 result의 크기는 result=[0]*2가 된다.
visited는 일종의 checklist로써 방문 흔적을 남기기 위한 방명록과 같다.
visited[i]=0이면 " i인덱스에 해당하는 arr의 요소"를 아직 방문하지 않았다는 것을 의미하며,
visited[i]=1이면 "i인덱스에 해당하는 arr의 요소"를 방문했다는 것을 의미한다.
다만, DFS의 경우 foward와 back을 하기 때문에 back할때는 해당 방문했던 곳을
다시 visitied[i] =0으로 만들어준다.
아래의 보충자료를 보자

선 위에 있는 0, 1, 2는 순회대상이 되는 arr의 index를 의미함과 동시에 이미 "해당 index에 해당하는 arr의 요소를 이미 방문했음"을 의미한다. 방문을 했다면, visited[i] = 1이 된다.
결과적으로 if조건문에서 visited[i] =1인 경우에는 조건탈락이므로 중복되지 않게 arr의 요소를 탐색하게 된다.
가장 좌측 하단의 경우 위에서 아래로 내려올 때 arr[0] 인덱스는 이미 방문했기 때문에 visited[0]=1이 되므로 DFS(2)는 호출되지 않는다.
그러면 다시 back을 해서 DFS(1)로 오게 되고, 다시 arr의 index가 1인 곳을 방문하게 된다. 그리고 arr[1]의 요소를 result [1]에 대입하게 된다.
L=2에 도달했을 때 result에는 [1, 2]가 담기게 되고, 이것을 깊은 복사(deep copy)를 통해 answer리스트에 담는다.
추가 적으로 주의할 점
▶ 재귀함수의 "종료조건"에서 return 문이 있어도 되고, 없어도 된다. 재귀 함수는 호출될 때마다
새로운 호출 스택을 생성하며, 재귀 함수 내에서 base case를 만나면(탐색이 더 이상 가능하지 않을 때)
해당 호출 스택은 종료되고, 호출된 함수로 되돌아가며, 이를 반복하여 최종적으로
main(여기서는 solution함수)함수로 돌아와 프로그램이 종료된다.
따라서, return 문이 없더라도 재귀 함수는 정상적으로 종료될 수 있다.
▶ answer.append(result)이 틀리고, answer.append(result[:])가 올바른 코드인 이유
→answer.append(result)에서 result는 기존의 result리스트를 가리키는 포인터이며,
→answer.append(result)는 answer리스트에 result리스트를 추가하는 것이다.
▶ answer.append(result[:])에서 result[:]는 result리스트의 복사본을 생성한 것이다.
이 경우 answer.append(result[:])는 answer리스트에 result리스트의 복사본을 추가하는 것이기 때문에
result리스트가 변경되더라도 answer리스트는 영향을 받지 않는다.
▶ 보충자료의 하단 좌측에 그림을 보면, result에는 주소인 100번지가 저장되어 있고, 동일하게 [ 1, 3]을
가리키고 있다. 따라서 기존에 저장되어 있던 [1, 2]가 [1, 3]으로 바뀌게 되는 bad 케이스가 발생할 수 있다.
너무 짧게 설명한 것 같아서 아래의 링크를 첨부한다.
https://crackerjacks.tistory.com/14
파이썬 (Python) - 깊은 복사 (Deep Copy)
파이썬 (Python) - 깊은 복사 (Deep Copy) 알고리즘을 풀다 보면 원본배열의 보존을 위해 배열을 복사할 필요를 느낄때가 많다. 객체를 무작정 복사해서 사용하면 원본 객체가 핸들링되어 데이터가 변
crackerjacks.tistory.com
이제 "피로도"를 설명하겠다.
#for문 안에 재귀함수가 있는 경우
#answer,N 전역변수, visited 전역배열
answer = 0
N = 0
visited = []
def dfs(k, cnt, dungeons):
#2단계: 함수 안에 있는 지역변수answer를 전역변수화 시킨다. answer는 전역변수이다.
global answer
# print("k=", k, "cnt=", cnt, dungeons)
if cnt > answer: # 1단계:비교 등호를 사용하면 인터프리터가 answer가 지역변수로 간주해버린다. 그런데 answer에 할당된 값이 없다.
answer = cnt
for j in range(N):
# print(k, dungeons[j][1], cnt)
if k >= dungeons[j][0] and visited[j]==0:
visited[j] = 1 #방문하려는 곳은 1로 체크
dfs(k - dungeons[j][1], cnt + 1, dungeons)
visited[j] = 0 #back하려는 경우에는 0로 되돌려 놓는다.
def solution(k, dungeons):
global N, visited
N = len(dungeons)
visited = [0] * N
dfs(k, 0, dungeons)
return answer
k = 80
dungeons = [[80,20],[50,40],[30,10]]
print(solution(k, dungeons))▶ def(k, cnt, dungeons)안에 있는 answer변수에 global이라는 키워드를 붙여서,
함수 내에 있는 answer지역변수를 전역변수로 바꾸어준다.
▶ 이렇게 해야 def함수가 재귀호출이 반복적으로 일어나더라도, 값이 초기화 되는 일 없이 cnt값이 지속적으로
반영될 수 있다.
▶ N, visited 모두 전역변수로 만들어서 solution함수와 def함수에서 모두 사용될 수 있도록 만든다.
▶ 여기서 중요한 점은 visited와 같은 checklist와 더불어서 k>=dungeons[j][0]이 추가 되었다는 점이다!!
즉 조건이 더욱 엄격해졌다.
▶ 즉 visited 즉 checklist를 통한 중복방문 방지 + 추가 조건(k>=dungeons[j][0])이 되었다.
▶ dungeons= [ [80, 20],[50, 40],[30, 10] ]
▶ 아래의 두 가지만 기억하자!!
▶ dungeons[j][0]은 비교대상, dungeons[j][1]은 실제로 빼는 값이다.

소거되는 logic은 두 가지이다.
if k >= dungeons[j][0] and visited[j]==0:의 반대 표현인
"이미 방문"을 했거나(visited[j]==1) 또는(or) k< dungeons[j][0]이 되어 "탈락"되는 경우이다.
가장 좌측을 보면 arr의 0번 index는 이미 방문했으므로 다시 arr의 0번 index를 방문하지 않는다.
def호출X
그리고 가운데 부분의 경우 k= 40 < duns[0][0] =80 이므로 "탈락"이다. 따라서 def는 호출X
최종적으로 cnt의 최대값은 3이 되므로 answer=3이 정답이 된다.
다시 한번 강조한다.
dungeons[j][0]은 비교대상, dungeons[j][1]은 실제로 빼는 값이다.
최종적으로 요약해보면,
1. 순열을 이용한 중복 방문 방지
2. if문에서 k>=dungeons[j][0]의 추가 조건을 이용한 탈락
3. global 키워드를 사용한 함수내에서의 전역변수 사용
4. return문이 없어도 base case(더 이상 탐색할수 없는 상태)를 만나면 재귀함수는 종료
글쓴이도 이해하는데 오래걸렸다. 위에 있는 보충자료를 펜으로 그려보길 바란다.
print문을 몇번을 찍어보았는데도, 이해가 되지 않았다. 손으로 그려보길 추천한다.
조합
#조합의 경우 체크리스트를 이용하지 않는다.!!!!!
#n은 1~n까지의 숫자
#r은 뽑을 개수
#i는 뻗는 가지
result = []
answer = []
def dfs(L, s, n, r):
if L == r:
answer.append(result[:])
return
for i in range(s, n+1):
result[L] = i #cf) 순열의 경우 result[L] = arr[i]
dfs(L + 1, i + 1, n, r)
def solution(n, r):
global result, answer
result = [0] * r
answer = []
dfs(0, 1, n, r)
return answer
print(solution(3, 2))▶ s는 start를 의미하며, 1부터 시작한다.
▶ L은 깊이를 의미하며, result의 index를 의미하기도 한다.
▶ i는 변하는 숫자를 의미한다.
▶ dfs(L+1, i+1)이 for i in range(s, n+1)에 영향을 주어서 깊이(L)이 증가할수록 s는 i+1부터 시작한다.
보충자료1

보충자료2
